MMORPG Data Storage (Part 2)
All the simplest, and probably most reasonable, designs entail that a client will only ever be connected to a single game server at a time. This implies that once in a while the client will have to switch from one server to another. As mentioned earlier, this could be when he enters through an instance portal into a dungeon, or if he takes the boat to another continent or island.
As a sequence diagram it might look something like this:
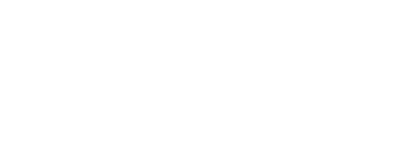
The client requests to disconnect from the first game server, which will immediately save the latest progress data to the central database. When the operation has completed it will send a response back to the client, indicating that now it’s safe to initiate a session with the other game server. After connecting to the other game server, it will load the player progress that was just saved by the first one.
Like we’ve heard before, if everything always worked as intended, this would be all there’d be to it. But, alas, consider the following scenario:
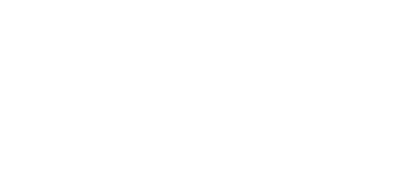
Remember that the game server can crash at any time, or maybe it’s just the client losing its connection. What is the client supposed to do in this situation? It doesn’t know what’s going on, it just sees the connection disappearing. On the sequence diagram, the server boom is visualized after the client sent the disconnect request, but it doesn’t really matter when it happens. The fact of the matter is that the client sits back without a connection. Usually the player will see some kind of slightly infuriating error message. Maybe he just completed some difficult quest or looted a rare item from a monster.
After the player clicks the “OK” button on the error message, usually you’d want to try and connect him back to the same game server. If it was just a network hiccup, the game server might keep the session alive for a while, hoping the player comes back.
Here we see a client crash and a player frantically trying to restart the game, which is pretty much equivalent to losing the connection:
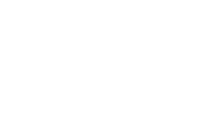
All this is great as long as we’re talking about a client crash or network issue where, usually, the client can just connect back to the same game server. But, what if the game server crashed? Usually the game server will restart after a crash, but it’s going to have lost its entire state. It could also be that the game server isn’t going to come back straight away:
- Maybe there is a deployment issue.
- Could be network issues at the cloud provider.
- The virtual machine hosting the game server could have gone bonkers.
- A bad hotfix.
- Someone tripping over a network cable in a data center.
- An act of god.
- Some random configuration issue.
Many things can go wrong, but it all boils down to the client deciding what to do. Eventually it will need to connect to another game server, without being 100% certain about what happened with the previous one. Don’t forget the very impatient player who just got disconnected.
So, he connects to some other game server which will load his latest progress data from the database. It should be quite obvious that we can’t really know if it is, in fact, the latest data. The player will know, though, when he sees that the monster is still alive and the rare item isn’t in his inventory.
This might not actually be too likely a problem, if the game server is saving progress data continuously. If any progress is lost, it can’t really be that much. On the other hand, you’ll probably want to have some kind of system in place to limit the amount of writing to the database. Maybe you’re saving at most every 10 or 20 seconds. Anyway, you can’t really do anything about it: when the game server crashed, all progress since last save was lost. It becomes a bit of a cost versus benefit situation: the shorter you make the minimum time between saves, the less data will be lost during a crash, but the more it will cost to host your database.
Let’s look at a more nefarious problem.
Game server network issues and infinite loops⌗
We already talked a bit about game server network issues. Imagine a game server losing its connection to the database. All the players connected to it are still merrily playing the game, not knowing that it’s not actually able to save their progress. Every attempt the game server does at saving to the database fails, but it’s not giving up. It keeps retrying until it works.
Now imagine a client that needs to switch to another game server. Looking at the server-switching sequence diagram from earlier, the client will never get an OK response back from the server, so it can’t really proceed. In this particular case we could just tell the player “Sorry, you can’t do that right now, please try again later.”.
What if we’re talking about a client disconnect or crash? Maybe we can’t reconnect to the same game server, after all it’s having some kind of network issue. While the game server might not have any clients left, it still has a lot of precious player progress data that it wants to save, but can’t.
Then suddenly the game server network issues are solved and it can reach the database again. Huzzah! Thousands of save requests are shoveled into the database in an instant.
Alternatively, what about some kind of infinite loop in the game server due to a bug. It might not actually be infinite, maybe it’s just going to stall the game server for a while, but it’s enough for clients to leave and connect to another game server. After a while the game server wakes up again and continues saving progress data.
Meanwhile players have killed dragons, acquired epic loot, and completed quests on other game servers. It’s not pretty when all this is overwritten by old data.
Exclusive access⌗
You might think that sequence numbered blobs will save us, but alone they’re not going to prevent the problem. It’s quite easy to come up with a scenario where two game servers both think they’re in charge and will update the sequence number independently. You’ll end up with two parallel realities and you don’t know which one is the correct one. The sequence number of the bad reality might overtake the real one.
Sequence numbers, however, are still useful. It’s a bit of a belt and suspenders situation: we really don’t want those pants to fall down. We’ll return to sequence numbering at a later point.
What we can do to remove ambiguity regarding what game server is in charge:
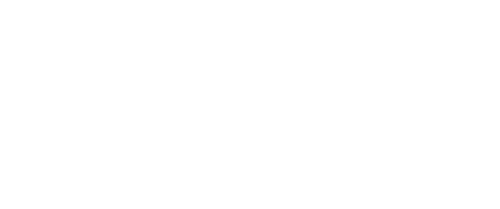
Essentially we want to put a global exclusive lock around a the progress data of a player. Easiest way to do this is to assign every game server a unique ID as part of its configuration, we’ll call this the lock ID. Imagine the database looking something like this:
| Blob Key | Lock ID | Blob Sequence Number | Blob |
|---|---|---|---|
| 1 | Game Server A | 123 | (serialized progress data) |
| 2 | 45 | (serialized progress data) | |
| etc | etc | etc | etc |
Blob key could be some kind of player ID or it could be something derived from it. It’s what we’ll use to find the progress data of a player. In this example we can see that blob key 1 has been locked by Game Server A, while blob key 2 isn’t currently locked.
When trying to acquire a lock, a game server will try to insert its lock ID for the specified blob key, but it should only succeed if the lock ID field is empty or if its already locked by the same game server. If another game server has the lock, it’s good practice to wait a bit and try again as it’s not unlikely that the other game server is in process of unlocking. We’ll also need to have some kind of attempt limit or timeout, otherwise we could end up in a situation where it’s stuck forever. The player will likely be staring at a loading screen while this is happening.
When it’s time to release the lock, it should simply clear the lock ID field, but it should verify again that it still has the lock. We should be careful not to clear the lock of another game server. Whenever we’re trying to save a blob, we should also check that we still have the lock.
Alternative ways to lock⌗
If you’re so inclined, you can move the locking somewhere else. Imagine you don’t want to have a direct mapping between a player ID and a single blob: maybe you want to have multiple blobs per player and you want to lock all of them at the same time. The lock acquisition logic gets a bit wonky when you want to acquire multiple in one go. In that case it seems more convenient to have a separate table for locks:
| Lock key | Lock Sequence Number | Lock ID |
|---|---|---|
| 1 | 9001 | Game Server A |
| 2 | 1234 | |
| etc | etc | etc |
The logic is the same when applying a lock, we just need to increment the Lock Sequence Number when we successfully acquire it.
The main blob table then looks something like this:
| Blob Key | Lock Sequence Number | Sequence Number | Blob |
|---|---|---|---|
| 1 | 9001 | 123 | (serialized progress data) |
| 2 | 1234 | 45 | (serialized progress data) |
| etc | etc | etc | etc |
When saving a blob, we’ll verify that either the entry doesn’t exist or the lock sequence number matches the one we got when we acquired the lock. But wait, how does the lock sequence number get into the blob table? We can put it there when we read the blob, which always happens right after we acquire the lock. Usually the new lock sequence number value will be larger than the previous one in the blob table, but we can’t rely on that as the lock table could have been lost and reset since last time. Numbers might all be reset. Since the lock table isn’t strictly necessary for operation, we shouldn’t rely on it too much, so we should simply discard the old lock sequence number stored with the blob. All subsequent blob saves should match the lock sequence number, though, otherwise we know that some other game server has stolen the lock, somehow.
Note that it requires the fulfillment of a bunch of edge cases to arrive at the situation where a healthy game server loses the lock of one of its clients, but again, belt and suspenders. Better safe than sorry.
Do we really need to store the lock table in a database? We could, potentially, just run a lock server process with a big hash table of locks in memory, where all game servers connect. This would probably be fine 99.99% of the time, but we get some problems if this hypothetical lock server crashes and restarts. All the game servers would need to scramble to apply their locks again, which could get messy. It seems safer to persist locks on disk. Besides, we can store more useful meta data with the locks, but we’ll talk about that at a later point.
My game server went kaboom!⌗
What happens with the locks of a game server that suddenly disappeared off the map? The locks are going to stay locked and other game servers will wait indefinitely to access the blobs. Most of the time it’s safe to assume that if a client has been waiting for a certain amount of time for their blob to be unlocked, we should just proceed and forcefully apply a new lock, overriding the existing one. Optionally we can present this decision to the player, whether or not he wants to take the chance, although it will surely be confusing the average player. These forceful unlocks make it important that game servers always check if they still have the lock, whenever they’re saving data.
Some made up numbers⌗
Let’s forget about locking mechanisms for a bit and go back to blob storage. I can imagine that some readers might think that it seems crazy to serialize and save player progress data pretty much all the time. After all, it’s going to be mostly the same data saved over and over again. Often an updated blob will only have a couple bytes that are different from the previous one. Serializing a new blob, sending it over the network, and finally writing it to a database, it definitely seems like a lot of work.
We can do a little back-of-the-napkin math. Imagine a game where the average blob is 10 KB, which is quite reasonable if you’re very careful about how you serialize things. You can cram a lot of stuff into 10 KB if you avoid wasting space with strings and 16-byte GUIDs. Of course the serialization itself might need a little CPU time, but if you’re feeling creative you can surely come up with some optimization tricks. For example, your game server session object will probably consist of a bunch of different subsystems that can be serialized independently. You can cache the latest serialization of each of these separately. The final blob will then just be mostly a bunch of data copied from this cache.
You can also do some tricks to reduce how often you save things. For example, different kinds of changes to the player progress can be assigned different priority levels. Looting a rare item could be very high priority, while the player’s position in the world could be very low priority. Now, basically store the priority level of the highest priority change since last save. Use this level to come up with a maximum amount of time since last save allowed. In my current project this technique results in an average of 20-30 seconds between saves. Let’s say 20 seconds to be conservative.
10 KB every 20 seconds = 500 bytes/second per client.
A game server with 1000 clients will send 0.5 MB/second back to the central database. This is not something I’d worry too much about. Furthermore, with most cloud providers, network traffic within a data center is very cheap or even free.
My central database is on the other side of the planet⌗
So, maybe you have game servers deployed all around the world. Players will usually have the best, lag-free experience if they’re connected to a game server geographically close to them. If you’re using a realm-based approach, you can designate every realm to a specific region. For example, you can have North American realms, European realms, Asian realms, etc. If each realm is completely isolated from other realms and has its own central database, you can put everything related to a single realm into the same data center. With no realms it’s not that straightforward, your central database is likely to not be hosted in the same data center as your game servers.
Using AWS as an example, it costs something like 2 cents per GB to transfer data between data centers. Using the example from before, a player will need to play 24/7 for more than three years to cost you one dollar in database network traffic.
These numbers might be different for your specific game, so maybe you’re still worrying about this cost, or maybe you’re worrying about the load it’s going to put on the central database. In that case we can do this:
Let every game server have its own little temporary database:
All saves during the session will go into the local temporary database of the game server. When the client disconnects, his progress data will be sent to the, potentially far away, central database. If a game server crashes and restarts, the first thing it will do is to read the contents of its local database and send everything in it back to the central one, obviously checking if it still has the locks. Everything can be unlocked cleanly.
Now what happens when the game server goes kaboom and never restarts again? First of all it will still have all the locks in the central database, which we need to handle with automatic forceful unlocks like discussed earlier. Secondly, now we lost absolutely all progress from all current sessions, because they we’re only stored on the local database which is now swallowed by a shark, or whatever. Because of this it seems like a good idea to still continuously save back to the central database, but maybe only every 10 or 20 minutes, instead of every 20 seconds.
It’s worth noting that if you use local temporary databases like this, a persistent locking mechanism becomes much more important. When every game server has a disk attached to it full of the latest player progress data, it becomes much more likely that some of it get “stuck” and is submitted back to the central database at a later point, where it’s going to overwrite newer data. Like, let’s say a game server crashes, which will leave its local data in limbo until it restarts. But what if it doesn’t restart immediately? Maybe something prevents it from restarting all together, until someone changes some configuration a month later, where it will then try to submit its data back. If a locking mechanism is used, it will see that it no longer has the locks, and thus shouldn’t overwrite anything.
Wrapping up the second part⌗
The main takeaway from the blog post is that we need some kind of exclusive locking mechanism to protect accidental overwrites of blobs. Besides introducing general fault tolerance, this allows robustly having client switching between game servers while playing.
At this point I feel like we’ve covered all of the main points of MMORPG data storage from a high-level point of view. In the next post of this series we’ll delve deeper and look into the “black box” we’ve so far used as a database.