Adding Offline Mode and Custom Servers to an MMORPG
Recently the Stop Killing Games movement got a lot of attention and sparked a lot of debate (and flame wars). While I’m not exactly planning on killing my homemade MMORPG Trolddom, it inspired me to look into making it “kill proof” with an offline mode and support for custom servers. It seemed like a fun little on-and-off summer project at the time. In this blog post I’ll go into details about the challenges of getting to the finish line.
To get the definitions straight: by offline mode I mean playing the game locally on your PC like a single-player game, without being connected to the internet. By custom servers I mean allowing players to run the entire server environment themselves.
Sir, this is an MMORPG⌗
It seems like the majority of multiplayer games these days are designed with a live service business plan in mind. Even games which fundamentally revolve around short sessions of multiplayer action are now sold as always-online games, without support for player hosted servers. This has been going for a long time now, as businesses are constantly trying to find ways to become profitable, in a game industry that becomes more competitive every year.
With all these games tied (tightly) to online services, a lot of players have become quite disillusioned with the whole situation. I don’t want to waste valuable blog real estate on ranting too much about this topic, though, as it seems like it has already been done to death. My opinion about it is quite inconsequential, anyway. To me I saw it mostly as a technical challenge that triggered my let’s write a bunch of code and see what happens instinct.
But why add an offline mode, or even custom servers, to an MMORPG? Most people would probably agree it’s one of the genres of games where always-online actually makes sense. You could easily argue that, from a business perspective, it’s quite a stupid idea. Luckily (or unfortunately) I’m not really bound by silly notions of whether something is stupid or not, so let’s dive right into it.
Architecture of Trolddom⌗
It was never my intention to be able to “un-live-service” Trolddom, so while putting everything together it wasn’t something I prepared for. This is, obviously, something that applies to most online games these days. Depending on various factors it might be quite easy, practically impossible, or somewhere in between, to stitch these features to an existing online game. My initial assumption was that it would be closer to the easy side of the scale than the other, mainly based on the fact that, after all, it’s a solo project with a complexity much lower than some crazy AAA game. As usually it turned out to be a bit more complicated than I thought it would be.
In order to provide a structured overview of the different things that needed to be done, let’s first look at the overall architecture of the game from an online service point of view.
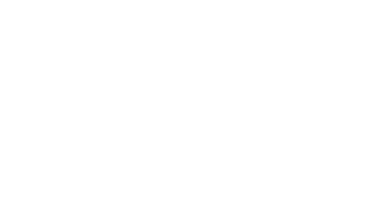
The whole things is probably best explained by a (simplified) step-by-step of how the player (the client) starts the game and enters the world:
- Client obtains an Encrypted Application Ticket from Steam. It contains the unique Steam ID of the player and also proves that they own the game.
- Client connects to Gateway and uses the Encrypted Application Ticket to authenticate. It will decrypt the ticket, check that it’s valid, and extract the Steam ID. It then queries the PostgreSQL database for the account. If it’s not already there, it is created. Gateway creates an encrypted auth token containing the account ID associated with the account and returns it to the client. This auth token is what is used to authenticate the client with other microservices.
- Client gets the list of realms from Gateway and presents the user with the list (if there is just one, it will pick it automatically).
- When the player has selected their realm, Client connects to the Realm service that hosts that particular realm. The realm session manages a list of all connected clients.
- If the realm session wasn’t already active, Realm will apply a lock on the realm data through Lock and then load it from Blob. This realm data contains the persistent state of the realm, for example power rankings of deities and stuff like that.
- Realm will tell Client when it’s attached successfully (potentially not immediately, in case of a queue).
- Client will then ask Gateway for a list of characters associated with the current realm. The player will be presented with options to select or manage characters. Client will also connect to the Messaging switchboard which allows clients to pass asynchronous messages (like invites) to each other.
- The player selects a character, which will make Client request a character token from Gateway. This contains information about the character, such as current map and the unique character ID.
- The character token is submitted to Realm as a spawn request. The server will then try to figure out what instance of the requested map to assign the player to. If no instance is available, or they’re all at max capacity, a new instance is created on a suitable Game server.
- Client connects to the assigned Game server and tells it what instance it wants. A session is created for the player.
- If the instance isn’t currently active on Game and needs to be created, the server will first lock the instance data through Lock and then obtain it from Blob. This instance data contains persistent information like what bosses of a dungeon are dead.
- Game locks the character data through Lock and gets the it from Blob.
- Client starts receiving game updates from Game. The server will regularly save updated character data back to Blob while the player is connected.
- When the player logs out, Game will make sure the latest character data is saved and then it will be unlocked through Lock.
Whew, that was a bit of a handful even when grossly simplified. I’ve also left out a few microservices used for monitoring and logging. The main take away is that we’ve got a bunch of microservices and a bunch of connections all over the place. Blob and Lock wraps a Jelly blob node and lock node respectively. I’ve rambled more about data storage in some earlier blog posts. Group handles the persistent state of player parties, guilds, raids, etc.
Using microservices seems to be the default these days, but it could easily be considered as over-engineering for a game like Trolddom. The alternative would be to just have a single unscalable monolith of a server that would just take care of everything and it would still be able to handle thousands of concurrent players for the same hosting cost. Needless to say, I never managed to get anywhere near that many players online at the same time. I do, however, like doing things the right way, so I architected stuff to be quite scalable. The main limiting factor is the number of players concurrently on the same open world map (or instance), which is really more of a gameplay limit than a technical limit. It kinda sucks when a hundred players are trying to farm the same monster spawns.
Microservice management⌗
What is a microservice exactly? Often a microservice will be corresponding to a single process running on a virtual machine, somewhere in the cloud. Usually you’ll probably run multiple microservices on the same virtual machine. If your game doesn’t have that many players, you can probably get away with running everything on the same virtual machine. Later, if you’re lucky enough to get too many players, you can spin up some more virtual machines and spread out your microservices. You might also want to run multiple instances of the same one (like more Game servers).
This is all great, but when deploying your microservices, it can get quite bothersome if you have a ton of different processes running on the same machine. It’s so much easier if you just have one, and I like easy because I’m lazy. For this reason I have a server module manager which essentially manages a bunch of microservices running inside the same process. The downside is that if one microservice segfaults, it’s going to crash all the others as well. If I was really worried about this, I’d isolate Game (the most complex and therefore crashy) microservice in its own process. It hasn’t really been much of a problem so far.
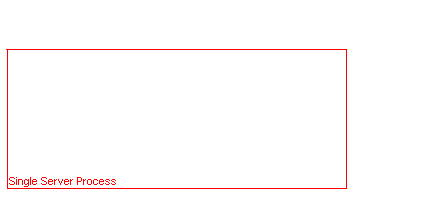
The diagram above illustrates this single server process approach that’s possible by using the server module manager.
So, why is this relevant? Well, one huge benefit of managing microservices like this is that in my special developer mode build of the game, I can run everything in the same process. The client and all of the backend. It’s immensely useful to be able to just hit F5 in Visual Studio and just launch and debug everything at the same time.
Isn’t that already an offline mode?⌗
Now that we have a nice superficial overview of how stuff works, it’s time to look into how offline mode and custom server support can be added to the game.
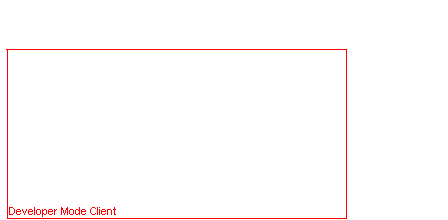
The developer mode build of the client, at a glance, already looks like offline mode, but notice that a PostgreSQL server is required for things to work. It’s used for a bunch of different data and not just accounts: in-game mail, auction house, character lists, guild names, generation of globally unique IDs, instance lock outs, and much more. We can’t really require players to install PostgreSQL on their PCs if they want to play Trolddom, so we need to get rid of it somehow. The plentiful connections between all the different nodes (within the process) are also problematic. While it still works, it seems a bit weird that a single-player game needs to listen on a bunch of different ports. If the player has a firewall it might ask some confusing questions or maybe even just block connections silently. Sure, some of these microservices doesn’t make sense in a single-player context. You’re not going to have guild members and who will buy your stuff on the auction house? We could definitely just disable a lot of these features in offline mode, but not all of them. Furthermore, it would require quite a bit of code to be changed or refactored, and there would need to be “are we in offline mode or not?” checks all over the place. From the perspective of a lazy developer, it’s a lot more convenient to keep as much as possible in place.
Offline mode networking⌗
Getting rid of the network connections, however, feels essential. How can we do it? If I had thought about this initially, maybe I would have made some kind of network abstraction layer where nodes on the network could pass messages to each other. To someone like me, who likes to over-engineer things, such an abstraction layer seems kinda neat. Imagine all these nodes passing messages to each other, without knowing anything about how they’re actually passed. Could be useful for automated tests without real networking. Then again, I’m here to cobble together a whole MMORPG, not just write code because it might be neat.
This is how most of the networking is implemented. Every microservice has corresponding client code, for example the Gateway service has a GatewayClient which wraps all the logic needed for communicating with the server. The GatewayClient object is responsible for maintaining a TCPConnection object that wraps a message stream and a socket connected to the server. It’s very straightforward and simple. If we wanted to abstract away the TCPConnection and replace it with a higher level message passing mechanism, things would get much more complicated.
But what about our offline mode? What’s the minimal, least intrusive, change we can do to get rid of these real connections? To me the obvious solution was to simply replace the lowest level part of the code with something else. In other words, use some kind of fake sockets. I looked around a bit and didn’t find anything I liked, so I ended up making my own little C library: fake-socket. It’s basically a drop-in replacement for the normal unix socket API. Works pretty much the same, but (fake) sockets can only be connected within the same process. If you want to play around with the library, beware that I’ve only implemented the features that I actually need for Trolddom (non-blocking IPv4 TCP sockets).
When I set out to do this, I naively predicted writing (and testing) fake-socket would be the most time-consuming part of all of this. Wasn’t the case, of course.
Fun with databases⌗
Embedding SQLite seemed like the obvious solution to avoid PostgreSQL. It’s a very neat little database you can embed straight into your programs. I was lucky that I had already abstracted all database queries into separate C++ modules, so I figured it would be simple enough to just have two implementations: one for PostgreSQL and one for SQLite. Then I opened up my SQL table definition file and remembered that I had 14 different tables with all kinds of weird things in them. How would I convert all those tables to something that works in SQLite? The idea of painstakingly recreating every table as SQLite-compatible SQL definitions made me quite uncomfortable. I also thought about the fact that later versions of the game might need changes to the table definitions. Players would have the offline mode databases locally on their PCs, which basically would require the game to automatically upgrade old databases with new table definitions. This would be require a lot of annoying code to be written, something I’d rather avoid.
Time for another shortcut. Basically, the SQLite backend doesn’t need to be that optimized. It doesn’t need to support my unrealistic fantasies of thousands of concurrent players. A nice simplification of the database table schema is to just use text strings for all columns. In that way, table definitions can be (mostly) reduced to just a list of strings representing column names. Upon initialization it can simply just add any column that’s not already there.
The accounts SQLite table can simply be defined in code like this:
m_sqliteAccounts = aSQLiteManager->GetTable("accounts");
m_sqliteAccounts->Init(
"account_id",
{
"username", "steam_id", "create_time", "banned_until_time",
"permaban", "ban_message", "super_user", "token_id",
"password_hash", "password_salt"
}
);
The primary key column (in this case account_id) is handled specially and is always an auto-incrementing integer. No other indices are created, so some queries might be very slow.
Unfortunately I couldn’t get around having to convert every single query to work with SQLite. Some were very straightforward, others were really annoying. One particular case of past laziness bit me in the behind. When designing database systems together with microservices, it’s usually best practice to have strict ownership of database tables. For example, the accounts table is owned by the Gateway microservice and nobody else is going to touch that table. The following diagram illustrates a few of these database tables and microservices:
Well, turned out that I had taken one shortcut that I shouldn’t have. Both Group and Realm need to generate globally unique integer IDs so it was convenient to just let them use the same mechanism. This turned out to be a mess when suddenly we’re using an embedded database instead of a real one. Basically, we can’t have separate microservices access the same SQLite database at the same time. Fortunately, since we know that in this particular case they’re running in the same process, we can write some ugly spaghetti code to make it work anyway. This is all quite straightforward, but it really farts up the codebase.
In the end it took an awful long time to get SQLite integrated and I’m not particular happy with the result. Ideally we’d need a proper clean abstraction of the two database implementations, but it would be quite a lot of work.
Note that I’ve been talking about SQL databases only. Player progress data (and other blobs) were already stored in an embedded Jelly database, so that didn’t require any extra consideration.
Putting it all together⌗
Okay, so now we have an offline mode that doesn’t need PostgreSQL to run and doesn’t make any network connections. Was that it? No, now we need to think about all the glue that puts everything together.
Recall from previous diagrams how Trolddom relies on Steam for authenticating the user with an Encrypted Application Ticket? Part of this involves a secret key only known by Steam and me. This allows me to check on Gateway that the user actually owns the game. For offline mode, this becomes quite unnecessary. First of all I can’t embed the secret key in the client (then it would no longer be secret, d’oh). Second of all, we don’t really need to validate anything in this case. This means Gateway need a new unauthenticated steam ID mode.
We also need to think about how it all is presented to the player. The easiest solution would be to just have a bunch of command-line options. For example “-offline_mode” to start the game in offline mode and “-custom_server <IP>” to connect to a custom server. This seems a bit lame, though. Imagine some unsuspecting person in 200 years who wants to run the game. They’ll happily double-click on the .exe file, the game will start, but they’ll immediately be presented with an error message that it can’t connect to the server (which was wiped out by an asteroid many years prior). They’ll give up and just assume the game doesn’t work. It seems more reasonable to have some kind of UI for it.
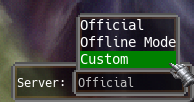
I added a very simple server selector UI in the front-end. I’m sure it could give a real UX designer a heart attack, but it is what it is.
When the player clicks on “Offline Mode” it will spin up a whole server environment inside the client and connect to it. The devil is in details and it took quite a bit of work to allow the player to switch back and forth between the different modes, mainly because the original code assumed only official servers.
What about custom servers?⌗
So far I’ve mostly been talking about offline mode and only mentioned custom servers fleetingly. Luckily there is some overlap between those two things. I was contemplating allowing custom servers to be managed from inside the game, but I convinced myself to keep it simple and require the players to run the server executable themselves. The process of running a custom Trolddom server isn’t super user friendly, but if someone cares enough about it, they should be able to figure it out. It will default to use the SQLite backend, so players don’t need to worry about installing PostgreSQL for this either. As default it will also point to the same databases as the ones used for offline mode, so players can potentially allow other players to join their world.
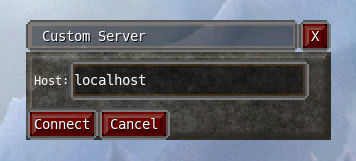
No NAT hole-punching or anything like that, so players will need to forward a bunch of ports manually if they want to use custom servers on the internet. I suppose that’s fine.
The whole custom server thing is quite simple as it’s essentially just a Windows version of the “official” Linux server. But, again… What about those Encrypted Application Tickets used for Steam authentication? Steam ID is the sole authentication supported by the game, which is usually wonderfully smooth as the player can just start the game from Steam and it will log in automatically. No need to worry about usernames, passwords, emails, or anything like that. We can’t do this with a custom server, because the secret key (that we use to validate tickets) needs to stay secret.
New can of worms unlocked.
Option 1: Use the same unauthenticated steam ID login mode as used by offline mode. This kinda sucks. Sure, it will be smooth from a user perspective, but it will be awfully insecure. Any hacker worth his salt would be able to pretend to be someone else when logging in.
Option 2: Implement a new username and password login mode that can be used with custom servers. This also kinda sucks. User account management is a notorious pain in the behind. We need to deal with players who forget their passwords. We need to be able to send emails. What about two-factor authentication? Please, no. There was a reason why I went with pure Steam authentication in the first place.
In the end I went with (1) as default and a watered down version of (2) as an extra option. I simply skipped all the horrible password reset and email parts. I figured that if someone really wants to set up their own fully fledged server environment, then they can deal with it themselves outside of the game (with some kind of website, probably).
Key takeaways⌗
This blog post have become way too long, so I’ll try to wrap it up as quickly as possible.
You want to have an offline mode and allow custom servers for your, otherwise, very online game? You should try to plan ahead, i.e. don’t be like me and glue it on later.
- Think about how to allow different kinds of user authentication. Steam authentication is amazing, but it obviously requires Steam. Don’t code yourself into a corner where everything expects a specific mode of authentication. This applies to both offline mode and custom servers.
- Think about databases and how they’ll work when run locally by players. This applies mostly to offline mode. For custom servers it’s probably not too unreasonable to expect players to run something like PostgreSQL. It depends how user friendly you need to be, I guess.
- For offline mode I was “lucky” that I wrote both client and all the different servers in the same language (C++). This allowed me to easily embed everything in the same process. If I had used a bunch of different languages it would have been a total mess.
- If you rely on external systems managed by third parties, you’ll also have a much harder time. For example, if half your backend is implemented as AWS Lambda “serverless” code, you’re going to have a bad time. Managed database solutions can also complicate things.
- Maybe abstract your network communication slightly higher than TCP connections and sockets.
- And, finally, structure your client code accordingly. Avoid assumptions about how the player is authenticated and what servers they’ll be connecting to.
Even if you aren’t sure if you’ll eventually add these features to your game, it might be a good idea to leave the door open. It might be slightly more work up front, but down the line everything will be a lot smoother. I’m also fairly certain that designing your systems with these things in mind, will result in overall cleaner code.